The HTTP part 4 - Multithreading
The problem
So far we managed to build a server that is single threaded. It means that processing requests are managed by one thread. When a response is prepared, all other incoming requests are queued. This leads to several problems.
Only one core is utilised
It’s not uncommon to run a server on a machine with 4, 8 or more cores. With a single-threaded model, only one of those core is utilised.
Slow response
What if we’ve got an app that reads something from a database on a request, but the database is having problems? Now we are waiting for the database to return records while other users send more request to our app. They have to wait for a first request to be finished.
Slow client
What if everything is fine with our system, but a client that connects to our server is slow? Our server is waiting for the client to send the request and cannot simultaneously read requests from other clients. What’s more, we did not set any timeouts which means that one client that connects to our server that forgot to sent a request essentially kills our server.
Multithreading
We can partially solve some of the problems by making our server multithreaded. The good news is that it is really easy to do so.
class Server(
val handler: Handler,
val port: Int,
val maxIncomingConnections: Int = 10,
val maxWorkerThreads: Int = 50
): AutoCloseable {
private val logger = LoggerFactory.getLogger(Server::class.java)
private val serverSocket = ServerSocket(port, maxIncomingConnections)
private val handlerThreadPool = Executors.newFixedThreadPool(maxWorkerThreads) // 1
private val acceptingConnectionsThreadPool = Executors.newSingleThreadExecutor()
init {
logger.info("Starting server on port $port")
acceptingConnectionsThreadPool.submit(this::acceptConnections)
}
private fun acceptConnections() {
while (!serverSocket.isClosed) {
try {
acceptConnection()
} catch (e: Exception) {
when {
e is InterruptedException -> throw e
e is SocketException && serverSocket.isClosed -> logger.trace("Socket was closed", e)
else -> logger.error("Could not accept new connection", e)
}
}
}
}
private fun acceptConnection() {
val socket = serverSocket.accept() // 2
handlerThreadPool.submit { // 3
try {
handleConnection(socket)
} catch (e: Exception) {
logger.warn("Could not handle connection", e)
}
}
}
private fun handleConnection(socket: Socket) {
socket.use {
val input = it.getInputStream().bufferedReader()
val output = PrintWriter(it.getOutputStream())
val response = try {
val request = Request.fromRaw(input)
handler(request)
} catch (e: RequestParseException) {
logger.warn("Could not parse a request", e)
Response(status = Status.BAD_REQUEST)
}
output.print(response.toRaw())
output.flush()
}
}
override fun close() {
logger.info("Stopping server")
serverSocket.close()
handlerThreadPool.shutdown()
handlerThreadPool.awaitTermination(1, TimeUnit.SECONDS)
acceptingConnectionsThreadPool.shutdown()
acceptingConnectionsThreadPool.awaitTermination(1, TimeUnit.SECONDS)
}
}
We added a thread pool (1) of max worker threads of 20. Now our server blocks on the acceptingConnectionsThreadPool to listen for a connection (2). When we’ve got the connection we immediately delegate reading a request, handling it and writing a response to another thread (3) from the handlerThreadPool. Now, when our server blocks on a slow database, client or anything else, it actually blocks a thread from handlerThreadPool, while we still can accept connections in acceptingConnectionsThreadPool.
Testing!
Let’s test if that works.
@Test
fun `should process multiple requests at once`() {
// given
val server = Server(port = 8090, handler = {
Thread.sleep(200)
Response(Status.OK)
})
// when
val completedRequests = CountDownLatch(3)
val clientPool = Executors.newFixedThreadPool(3)
repeat(3) {
clientPool.submit {
try {
val response = HttpUrlConnectionClient(connectionTimeout = 100, socketTimeout = 300)
.exchange(url = "http://localhost:8090", request = Request(path = "/", method = RequestMethod.GET))
if (response.status == Status.OK) {
completedRequests.countDown()
}
} catch (e: Exception) {
e.printStackTrace()
}
}
}
// then
// if server was single threaded then it would take at least 600ms (3 * sleep of 200ms)
completedRequests.await(500, TimeUnit.MILLISECONDS)
clientPool.shutdownNow()
// cleanup
server.close()
}
We slow down providing a response by 200ms and make 3 requests at once. Then, we check if all those requests are completed by 500ms (which is less than 3 requests of 200ms one by one). We run it and it passes.
We are under heavy load!
Ok, so let’s say our database, microservice or any external resource is lagging and now it takes a lot of time to respond. We are trying to respond to 20 clients at once, we’ve got a pool of 20 threads, so what happens to the next client that makes a request? The maxIncomingConnections is almost irrelevant now because we’re immediately accepting new connections, so the queue there should be empty most of the time. The new handler task is being submitted to the thread pool and it is queued in its internal queue. Where is this queue?
/**
* Creates a thread pool that reuses a fixed number of threads
* operating off a shared unbounded queue.
...
*/
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
We can see that Executors#newFixedThreadPool factory method creates a thread pool with unbounded LinkedBlockingQueue. Normally I would strongly suggest limiting the size of the queue because we can easily hit OutOfMemoryError filling queue with tasks, but in this case, we will hit another limit first.
File descriptors
Imagine that database is now taking forever to return query, our requests handling tasks are piling up on a queue. Keep in mind that before we submit a task to handlerThreadPool we accept a new connection. Eventually, what will happen is that we will hit a file descriptors limit! As you may remember from Part 2, every open connection creates a new file descriptor.
To see that we setup Vagrant VM changing it open files limit to 500
sudo bash -c "echo '* - nofile 500' >> /etc/security/limits.conf"
Then we can run wrk - a HTTP benchmarking tool from host machine that opens 1000 concurrent connections
wrk -c1000 -d10s -t1000 http://localhost:8091
And there we go, we’ve got an exception
Cvagrant@vagrant-ubuntu-trusty-64:~$ java -jar /project/naphi-0.1-SNAPSHOT.jar
Exception in thread "main" java.net.SocketException: Too many open files (Accept failed)
at java.net.PlainSocketImpl.socketAccept(Native Method)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409)
at java.net.ServerSocket.implAccept(ServerSocket.java:545)
at java.net.ServerSocket.accept(ServerSocket.java:513)
at org.naphi.Server.start(Server.kt:79)
at org.naphi.ServerKt.main(Server.kt:119)
The default limit on Ubuntu Vagrant was 4096 on Java process. You can easily bump it up, but keep in mind that every resource is finite. Every open socket cost us RAM, although as I mentioned in previous posts, you can bump this limit to even millions of file descriptors with proper tuning and large enough machine.
Can we be more graceful?
When we hit the file descriptor limit, our server either drops the connection or send RST packet. A client will most likely retry connection either by custom logic on RST or built-in TCP retries on dropped connection. Instead, we can return 503 Service Unavailable status code. What is interesting is that you can attach a Retry-After header which will suggest when the client should try again. If the client respects that, then you can avoid unnecessary requests.
Number of worker threads
Let’s say that database is taking 5 seconds to return a query. We’ve got 20 worker threads and in every thread, we are blocking for those 5 seconds. Essentially we can now respond with a maximum of 20 requests per 5 seconds = 4 requests/s. Additionally, let’s assume that we can spawn other connections to the database and we won’t kill it by doing so (not a real-world scenario). Theoretically, if we increase our pool to 200 workers we should get 40 requests/s.
How far can we go?
After changing maxWorkerThreads to 4000 I eventually got OutOfMemoryException. Every new thread costs us RAM, so be careful with that. Besides that, there is a limit on system processes in Linux. It’s 32 768 by default on my Vagrant machine.
vagrant@vagrant-ubuntu-trusty-64:~$ cat /proc/sys/kernel/pid_max
32768
But also more isn’t better. If the system is back to normal we end up with lots of redundant threads eating memory. The pool can scale down killing threads, but more working threads (actually working, not waiting for socket) means more context switching. Moreover, you have to be prepared to spin up thousands of threads, so you have to reserve machine with more RAM, even if for example only 20% of it is used for 90% of the time.
What is the right value?
Measure it. Start with some value that you feel will be ok. Then measure your thread pool utilisation (active threads / all threads) and size of the queue then check if you need to go lower or higher.
Name your thread pools
There is one thing we didn’t do. We didn’t name our thread pool! It is really helpful later on when you want to read logs or thread dump.
| Unnamed threads | Named threads |
|---|---|
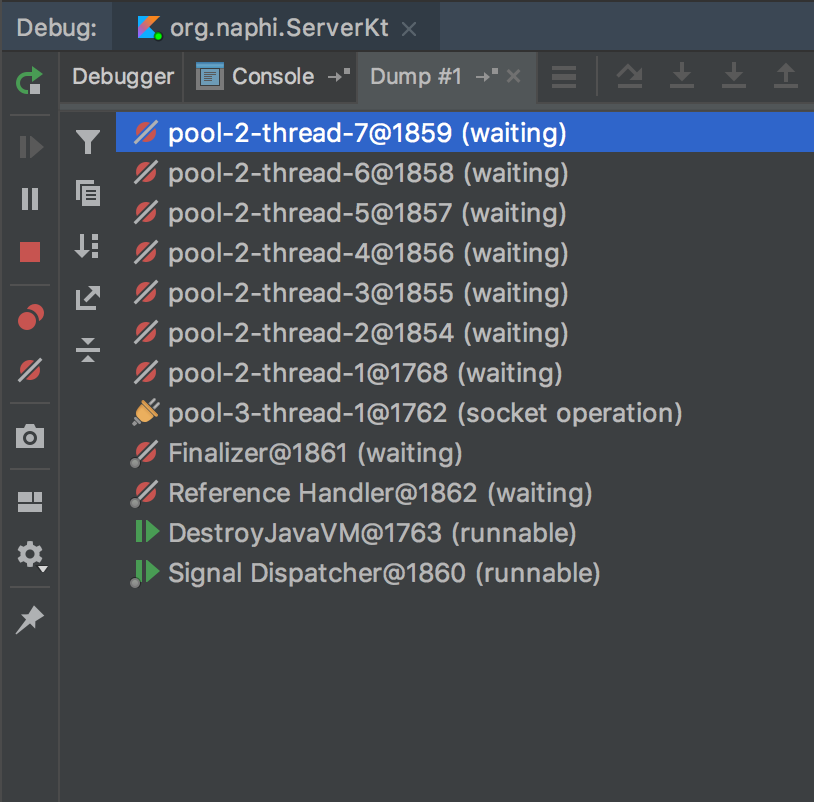 |
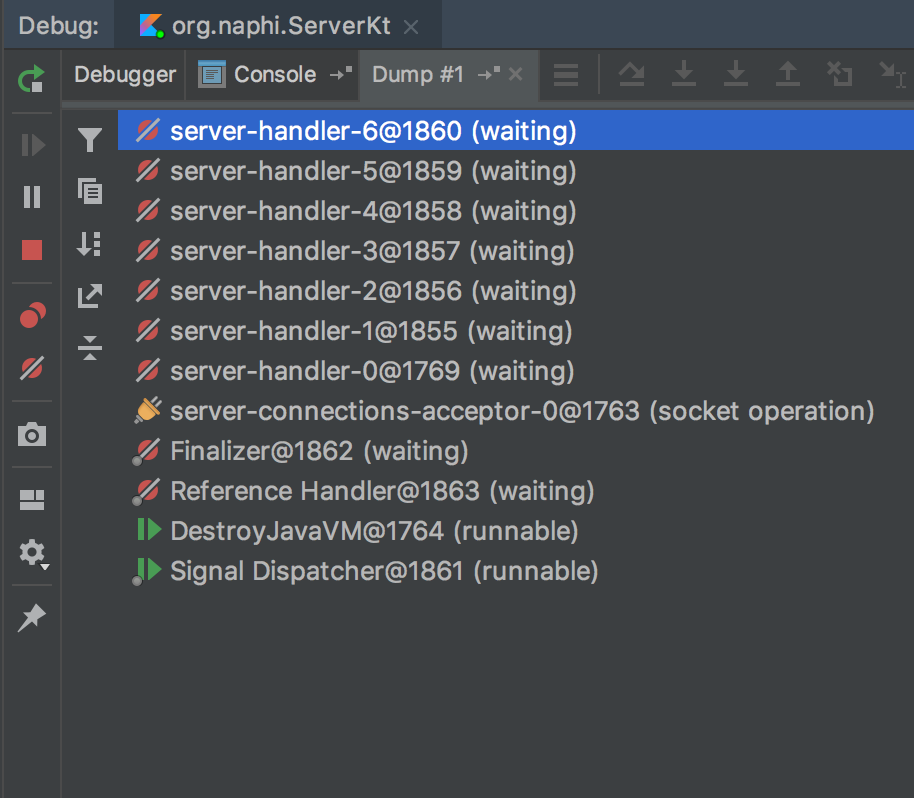 |
To name our thread pool we have to pass ThreadFactory instance. If you’ve got Guava on your classpath, use ThreadFactoryBuilder, which provides a nice API to create it. We don’t so we have to do it by ourselves.
private class IncrementingThreadFactory(val prefix: String): ThreadFactory {
val adder = AtomicInteger()
override fun newThread(r: Runnable) = Thread(r).also { it.name = "$prefix-${adder.getAndIncrement()}" }
}
And pass it to Executors.newFixedThreadPool like this
private val handlerThreadPool = Executors.newFixedThreadPool(maxWorkerThreads,
IncrementingThreadFactory("server-handler"))
private val acceptingConnectionsThreadPool = Executors.newSingleThreadExecutor(
IncrementingThreadFactory("server-connections-acceptor"))
Summary
We managed to change our server to the multithread version. We can now utilise all cores! A slow client finally won’t make others wait for a response (although multiple slow clients will). Next up - we will create a connection pool.
Other articles of the series
This article is a part of the HTTP series